331 lines
14 KiB
Markdown
331 lines
14 KiB
Markdown
# GPU-Jupyter
|
|
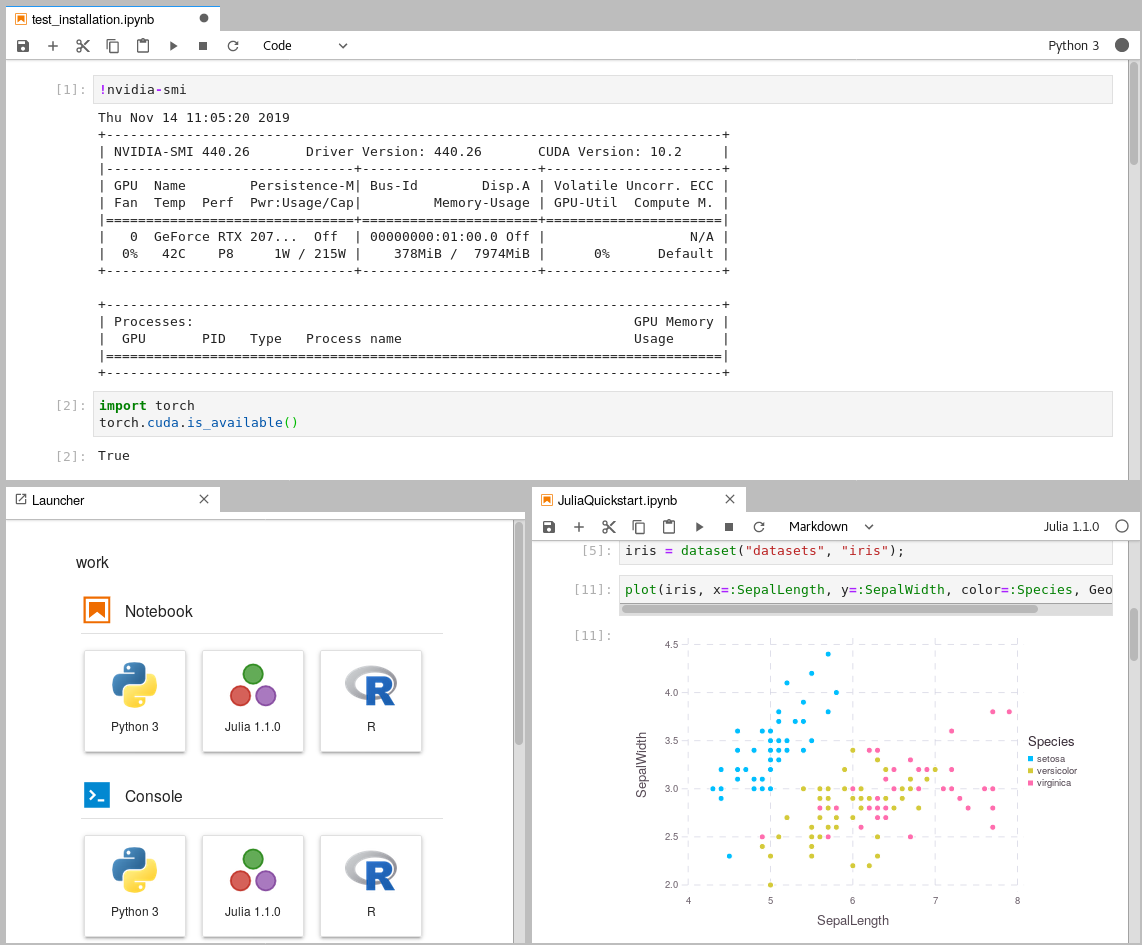
#### Leverage Jupyter Notebooks with the power of your NVIDIA GPU and perform GPU calculations using Tensorflow and Pytorch in collaborative notebooks.
|
|
|
|
|
|
|
|
First of all, thanks to [docker-stacks](https://github.com/jupyter/docker-stacks)
|
|
for creating and maintaining a robost Python, R and Julia toolstack for Data Analytics/Science
|
|
applications. This project uses the NVIDIA CUDA image as the base image and installs their
|
|
toolstack on top of it to enable GPU calculations in the Jupyter notebooks.
|
|
The image of this repository is available on [Dockerhub](https://hub.docker.com/r/cschranz/gpu-jupyter).
|
|
|
|
## Contents
|
|
|
|
1. [Quickstart](#quickstart)
|
|
2. [Build your own image](#build-your-own-image)
|
|
3. [Tracing](#tracing)
|
|
4. [Configuration](#configuration)
|
|
5. [Deployment](#deployment-in-the-docker-swarm)
|
|
6. [Issues and Contributing](#issues-and-contributing)
|
|
|
|
|
|
## Quickstart
|
|
|
|
1. A computer with an NVIDIA GPU is required.
|
|
2. Install [Docker](https://www.docker.com/community-edition#/download) version **1.10.0+**
|
|
and [Docker Compose](https://docs.docker.com/compose/install/) version **1.6.0+**.
|
|
3. Get access to your GPU via CUDA drivers within Docker containers.
|
|
You can be sure that you can access your GPU within Docker,
|
|
if the command `docker run --gpus all nvidia/cuda:10.1-cudnn7-runtime-ubuntu18.04 nvidia-smi`
|
|
returns a result similar to this one:
|
|
```bash
|
|
Tue Jan 5 09:38:21 2021
|
|
+-----------------------------------------------------------------------------+
|
|
| NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 10.1 |
|
|
|-------------------------------+----------------------+----------------------+
|
|
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
|
|
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|
|
| | | MIG M. |
|
|
|===============================+======================+======================|
|
|
| 0 GeForce RTX 207... Off | 00000000:01:00.0 On | N/A |
|
|
| 0% 40C P8 7W / 215W | 360MiB / 7974MiB | 1% Default |
|
|
| | | N/A |
|
|
+-------------------------------+----------------------+----------------------+
|
|
|
|
+-----------------------------------------------------------------------------+
|
|
| Processes: |
|
|
| GPU GI CI PID Type Process name GPU Memory |
|
|
| ID ID Usage |
|
|
|=============================================================================|
|
|
+-----------------------------------------------------------------------------+
|
|
```
|
|
If you don't get an output similar than this one, follow the installation steps in this
|
|
[medium article](https://medium.com/@christoph.schranz/set-up-your-own-gpu-based-jupyterlab-e0d45fcacf43).
|
|
The CUDA toolkit is not required on the host system, as it will be
|
|
installed within the Docker containers using [NVIDIA-docker](https://github.com/NVIDIA/nvidia-docker).
|
|
It is also important to keep your installed CUDA version in mind, when you pull images.
|
|
**You can't run images based on `nvidia/cuda:11.1` if you have only CUDA version 10.1 installed.**
|
|
Check your host's CUDA-version with `nvcc --version` and update to at least
|
|
the same version you want to pull.
|
|
|
|
4. Pull and run the image. This can last some hours, as a whole data-science
|
|
environment will be downloaded:
|
|
```bash
|
|
cd your-working-directory
|
|
docker run --gpus all -d -it -p 8848:8888 -v $(pwd)/data:/home/jovyan/work -e GRANT_SUDO=yes -e JUPYTER_ENABLE_LAB=yes --user root cschranz/gpu-jupyter:v1.2_cuda-10.1_ubuntu-18.04_python-only
|
|
```
|
|
This starts an instance with of *GPU-Jupyter* the tag `v1.2_cuda-10.1_ubuntu-18.04_python-only` at [http://localhost:8848](http://localhost:8848) (port `8484`).
|
|
The default password is `gpu-jupyter` (previously `asdf`) which should be changed as described [below](#set-password).
|
|
Furthermore, data within the host's `data` directory is shared with the container.
|
|
Other versions of GPU-Jupyter are available and listed on Dockerhub under [Tags](https://hub.docker.com/r/cschranz/gpu-jupyter/tags?page=1&ordering=last_updated).
|
|
|
|
|
|
Within the Jupyterlab instance, you can check if you can access your GPU by opening a new terminal window and running
|
|
`nvidia-smi`. In terminal windows, you can also install new packages for your own projects.
|
|
Some example code can be found in the repository under `extra/Getting_Started`.
|
|
If you want to learn more about Jupyterlab, check out this [tutorial](https://www.youtube.com/watch?v=7wfPqAyYADY).
|
|
|
|
|
|
## Build your own Image
|
|
|
|
First, it is necessary to generate the `Dockerfile` in `.build`, that is based on
|
|
the NIVIDA base image and the [docker-stacks](https://github.com/jupyter/docker-stacks).
|
|
As soon as you have access to your GPU within Docker containers
|
|
(make sure the command `docker run --gpus all nvidia/cuda:10.1-cudnn7-runtime-ubuntu18.04 nvidia-smi`
|
|
shows your GPU statistics), you can generate the Dockerfile, build and run it.
|
|
The following commands will start *GPU-Jupyter* on [localhost:8848](http://localhost:8848)
|
|
with the default password `gpu-jupyter` (previously `asdf`).
|
|
|
|
```bash
|
|
git clone https://github.com/iot-salzburg/gpu-jupyter.git
|
|
cd gpu-jupyter
|
|
# generate a Dockerfile with python and without Julia and R
|
|
./generate-Dockerfile.sh --python-only
|
|
docker build -t gpu-jupyter .build/ # will take a while
|
|
docker run --gpus all -d -it -p 8848:8888 -v $(pwd)/data:/home/jovyan/work -e GRANT_SUDO=yes -e JUPYTER_ENABLE_LAB=yes -e NB_UID="$(id -u)" -e NB_GID="$(id -g)" --user root --restart always --name gpu-jupyter_1 gpu-jupyter
|
|
```
|
|
|
|
This starts a container WITH GPU support, a shared local data volume `data`
|
|
and some other configurations like root permissions which are necessary to install packages within the container.
|
|
For more configurations, scroll down to [Configuration of the Dockerfile-Generation](#configuration-of-the-dockerfile-generation).
|
|
|
|
### Start via Docker Compose
|
|
|
|
The script `start-local.sh` is a wrapper for a quick configuration of the
|
|
underlying `docker-compose.yml`:
|
|
|
|
```bash
|
|
./start-local.sh -p 8848 # the default port is 8888
|
|
```
|
|
|
|
|
|
## Tracing
|
|
|
|
With these commands we can see if everything worked well:
|
|
```bash
|
|
docker ps
|
|
docker logs [service-name] # or
|
|
bash show-local.sh # a env-var safe wrapper for 'docker-compose logs -f'
|
|
```
|
|
|
|
In order to stop the local deployment, run:
|
|
|
|
```bash
|
|
docker ps
|
|
docker rm -f [service-name] # or
|
|
./stop-local.sh
|
|
```
|
|
|
|
|
|
## Configuration
|
|
|
|
### Configuration of the Dockerfile-Generation
|
|
|
|
The script `generate-Dockerfile.sh` generates a Dockerfile within the `.build/`
|
|
directory.
|
|
This implies that this Dockerfile is overwritten by each generation.
|
|
The Dockerfile-generation script `generate-Dockerfile.sh`
|
|
has the following parameters (note that 2, 3 and 4 are exclusive):
|
|
|
|
* `-c|--commit`: specify a commit or `"latest"` for the `docker-stacks`,
|
|
the default commit is a working one.
|
|
|
|
* `-s|--slim`: Generate a slim Dockerfile.
|
|
As some installations are not needed by everyone, there is the possibility to skip some
|
|
installations to reduce the size of the image.
|
|
Here the `docker-stack` `scipy-notebook` is used instead of `datascience-notebook`
|
|
that comes with Julia and R.
|
|
Moreover, none of the packages within `src/Dockerfile.usefulpackages` is installed.
|
|
|
|
* `--python-only|--no-datascience-notebook`: As the name suggests, the `docker-stack` `datascience-notebook`
|
|
is not installed
|
|
on top of the `scipy-notebook`, but the packages within `src/Dockerfile.usefulpackages` are.
|
|
|
|
* `--no-useful-packages`: On top of the `docker-stack` `datascience-notebook` (Julia and R),
|
|
the essential `gpulibs` are installed, but not the packages within `src/Dockerfile.usefulpackages`.
|
|
|
|
|
|
### Custom Installations
|
|
|
|
Custom packages can be installed within a container, or by modifying the file
|
|
`src/Dockerfile.usefulpackages`.
|
|
**As `.build/Dockerfile` is overwritten each time a Dockerfile is generated,
|
|
it is suggested to append custom installations either
|
|
within `src/Dockerfile.usefulpackages` or in `generate-Dockerfile.sh`.**
|
|
If an essential package is missing in the default stack, please let us know!
|
|
|
|
|
|
|
|
### Set Password
|
|
|
|
Please set a new password using `src/jupyter_notebook_config.json`.
|
|
Therefore, hash your password in the form (password)(salt) using a sha1 hash generator, e.g., the sha1 generator of [sha1-online.com](http://www.sha1-online.com/).
|
|
The input with the default password `gpu-jupyter` (previously `asdf`) is concatenated by an arbitrary salt `3b4b6378355` to `gpu-jupyter3b4b6378355` and is hashed to `642693b20f0a33bcad27b94293d0ed7db3408322`.
|
|
|
|
**Never give away your own unhashed password!**
|
|
|
|
Then update the config file as shown below and restart the service.
|
|
|
|
```json
|
|
{
|
|
"NotebookApp": {
|
|
"password": "sha1:3b4b6378355:642693b20f0a33bcad27b94293d0ed7db3408322"
|
|
}
|
|
}
|
|
```
|
|
|
|
|
|
### Updates
|
|
|
|
#### Update CUDA to another version
|
|
|
|
The host's CUDA-version must be equal or higher than that of the
|
|
container itself (in `Dockerfile.header`).
|
|
Check the host's version with `nvcc --version` and the version compatibilities
|
|
for CUDA-dependent packages as [Pytorch](https://pytorch.org/get-started/locally/)
|
|
respectively [Tensorflow](https://www.tensorflow.org/install/gpu) previously.
|
|
Then modify, if supported, the CUDA-version in `Dockerfile.header` to, e.g.:
|
|
the line:
|
|
|
|
FROM nvidia/cuda:11.1-base-ubuntu20.04
|
|
|
|
and in the `Dockerfile.pytorch` the line:
|
|
|
|
cudatoolkit=11.1
|
|
|
|
Then re-generate, re-build and run the updated image, as closer described above:
|
|
Note that a change in the first line of the Dockerfile will re-build the whole image.
|
|
|
|
```bash
|
|
./generate-Dockerfile.sh
|
|
docker build -t gpu-jupyter .build/ # will take a while
|
|
docker run --gpus all -d -it -p 8848:8888 -v $pwd/data:/home/jovyan/work -e GRANT_SUDO=yes -e JUPYTER_ENABLE_LAB=yes --user root --restart always --name gpu-jupyter_1 gpu-jupyter
|
|
```
|
|
|
|
|
|
#### Update Docker-Stack
|
|
|
|
The [docker-stacks](https://github.com/jupyter/docker-stacks) are used as a
|
|
submodule within `.build/docker-stacks`. Per default, the head of the commit is reset to a commit on which `gpu-jupyter` runs stable.
|
|
To update the generated Dockerfile to a specific commit, run:
|
|
|
|
```bash
|
|
./generate-Dockerfile.sh --commit c1c32938438151c7e2a22b5aa338caba2ec01da2
|
|
```
|
|
|
|
To update the generated Dockerfile to the latest commit, run:
|
|
|
|
```bash
|
|
./generate-Dockerfile.sh --commit latest
|
|
```
|
|
|
|
A new build can last some time and may consume a lot of data traffic. Note, that the latest version may result in
|
|
a version conflict!
|
|
More info to submodules can be found in
|
|
[this tutorial](https://www.vogella.com/tutorials/GitSubmodules/article.html).
|
|
|
|
|
|
|
|
## Deployment in the Docker Swarm
|
|
|
|
A Jupyter instance often requires data from other services.
|
|
If that data-source is containerized in Docker and sharing a port for communication shouldn't be allowed, e.g., for security reasons,
|
|
then connecting the data-source with *GPU-Jupyter* within a Docker Swarm is a great option!
|
|
|
|
### Set up Docker Swarm and Registry
|
|
|
|
This step requires a running [Docker Swarm](https://www.youtube.com/watch?v=x843GyFRIIY) on a cluster or at least on this node.
|
|
In order to register custom images in a local Docker Swarm cluster,
|
|
a registry instance must be deployed in advance.
|
|
Note that the we are using the port 5001, as many services use the default port 5000.
|
|
|
|
```bash
|
|
sudo docker service create --name registry --publish published=5001,target=5000 registry:2
|
|
curl 127.0.0.1:5001/v2/
|
|
```
|
|
This should output `{}`. \
|
|
|
|
Afterwards, check if the registry service is available using `docker service ls`.
|
|
|
|
|
|
### Configure the shared Docker network
|
|
|
|
Additionally, *GPU-Jupyter* is connected to the data-source via the same *docker-network*. Therefore, This network must be set to **attachable** in the source's `docker-compose.yml`:
|
|
|
|
```yml
|
|
services:
|
|
data-source-service:
|
|
...
|
|
networks:
|
|
- default
|
|
- datastack
|
|
...
|
|
networks:
|
|
datastack:
|
|
driver: overlay
|
|
attachable: true
|
|
```
|
|
In this example,
|
|
* the docker stack was deployed in Docker swarm with the name **elk** (`docker stack deploy ... elk`),
|
|
* the docker network has the name **datastack** within the `docker-compose.yml` file,
|
|
* this network is configured to be attachable in the `docker-compose.yml` file
|
|
* and the docker network has the name **elk_datastack**, see the following output:
|
|
```bash
|
|
sudo docker network ls
|
|
# ...
|
|
# [UID] elk_datastack overlay swarm
|
|
# ...
|
|
```
|
|
The docker network name **elk_datastack** is used in the next step as a parameter.
|
|
|
|
### Start GPU-Jupyter in Docker Swarm
|
|
|
|
Finally, *GPU-Jupyter* can be deployed in the Docker Swarm with the shared network, using:
|
|
|
|
```bash
|
|
./generate-Dockerfile.sh
|
|
./add-to-swarm.sh -p [port] -n [docker-network] -r [registry-port]
|
|
# e.g. ./add-to-swarm.sh -p 8848 -n elk_datastack -r 5001
|
|
```
|
|
where:
|
|
* **-p:** port specifies the port on which the service will be available.
|
|
* **-n:** docker-network is the name of the attachable network from the previous step,
|
|
e.g., here it is **elk_datastack**.
|
|
* **-r:** registry port is the port that is published by the registry service, default is `5000`.
|
|
|
|
Now, *gpu-jupyter* will be accessible here on [localhost:8848](http://localhost:8848)
|
|
with the default password `gpu-jupyter` (previously `asdf`) and shares the network with the other data-source, i.e.,
|
|
all ports of the data-source will be accessible within *GPU-Jupyter*,
|
|
even if they aren't routed it the source's `docker-compose` file.
|
|
|
|
Check if everything works well using:
|
|
```bash
|
|
sudo docker service ps gpu_gpu-jupyter
|
|
docker service ps gpu_gpu-jupyter
|
|
```
|
|
|
|
In order to remove the service from the swarm, use:
|
|
```bash
|
|
./remove-from-swarm.sh
|
|
```
|
|
|
|
|
|
## Issues and Contributing
|
|
|
|
This project has the intention to create a robust image for CUDA-based GPU-applications,
|
|
which is built on top of the [docker-stacks](https://github.com/jupyter/docker-stacks).
|
|
You are free to help to improve this project, by:
|
|
|
|
* [filing a new issue](https://github.com/iot-salzburg/gpu-jupyter/issues/new)
|
|
* [open a pull request](https://help.github.com/articles/using-pull-requests/)
|